这篇文章来探索一下一个 CUDA 优化的一个经典案例——FP32 矩阵乘法的优化,本文绝大部分代码、优化和分析都参考了这篇知乎文章 ,所以这篇文章基本上等同于学习记录,但自己走过一遍之后补足了一些其中忽略的细节。那么话不多说,就从问题描述开始吧!
问题描述 给定一个以行优先方式存储的大小为 $M \times K$ 矩阵 $\mathbf{A}$ 和同样以行优先方式存储的大小为 $K \times N$ 的矩阵 $\mathbf{B}$,要求计算 $\mathbf{C} = \mathbf{A} \times \mathbf{B}$,其中:
$$C_{i, j} = \sum_{k=1}^{K} A_{i, k} B_{k, j}$$
评测环境与测试结果 下面用于评测每个 Kernel 时间的测评环境是这样的:
CPU: AMD Ryzen 9 3900x GPU: RTX 2080 Ti (11 GiB) @ 250W OS: Arch Linux GPU Driver: 545.29.06 GCC/CUDA: 13.2.1/12.3.1 所有实验均选取 $M = N = 8192$, $K = 4096$ 作为输入矩阵大小,并采用 3 轮热身,评测 100 轮取平均值和标准差的方式得到运行时间。下表展示了所有 Kernel 的测试结果,仅供娱乐😝:
实现一:暴力 最朴素的方式就是开 $N \times M$ 个线程,编号为 $(i, j)$ 的线程计算 $C_{i, j}$,这样实现的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
__global__ void gemm_fp32_v1 ( uint32_t M , uint32_t N , uint32_t K , //
float alpha , float beta , //
const float * __restrict__ A , //
const float * __restrict__ B , //
float * __restrict__ C ) {
uint32_t y = blockIdx . y * blockDim . y + threadIdx . y ;
uint32_t x = blockIdx . x * blockDim . x + threadIdx . x ;
if ( y >= M || x >= N ) {
return ;
}
float sum = 0.0f ;
for ( uint32_t k = 0 ; k < K ; k ++ ) {
sum += A [ y * K + k ] * B [ k * N + x ];
}
C [ y * N + x ] = alpha * sum + C [ y * N + x ] * beta ;
}
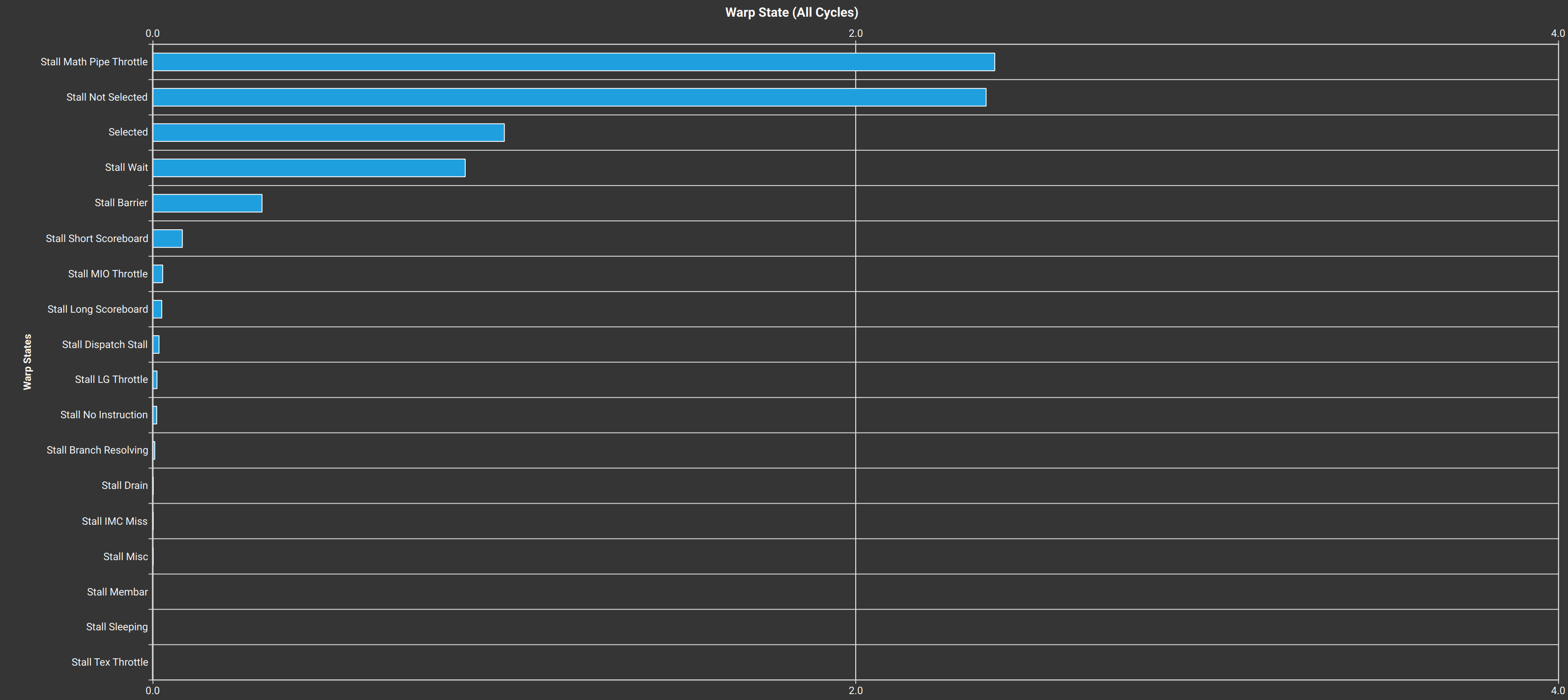
这个朴素的实现不出意外获得了很差的性能,只有 cuBLAS 性能的 7.9%,通过 Profiler 发现Stall Long Scoreboard 和 Stall LG Throttle,这表明这个 Kernel 被读写 Global Memory 的操作给限制住了。
如果说要知道是什么原因,我们可以分析一下这个朴素实现的内存访问模式,因为 GPU 的 Memory Transaction 都是以 Warp 为单位,所以需要以 Warp 为粒度来分析,下图展示了这个朴素实现中每个 Warp 中的内存访问模式,其中线程块的形状为 (32, 8):
暴力矩阵乘法中每个 Warp 的内存访问模式
如图所示,每个 Warp 会经历 $K$ 轮循环,在每轮循环中,一个 Warp 的 32 个线程会:
读取矩阵 $\mathbf{A}$ 中的 1 个元素,因而会触发广播 (Broadcast) 机制,即实际上只会发射 (Issue) 一个对 Global Memory 的 Transaction; 读取矩阵 $\mathbf{B}$ 中的 32 个元素,读取这些元素互不相同,因而不会触发广播机制,但因为这 32 个元素在内存空间中是连续的,因而最优情况下可以合并为一个 128 字节的内存访问; 执行 32 次 FFMA 运算,可以看作是 64 个 FLOPs 最后在循环结束时会写入 32 个元素到矩阵 $\mathbf{C}$ ,同样这些元素互不相同,但有可能触发内存的合并访问;
从内存带宽的角度来分析,每个 Warp 在每轮循环中从 Global Memory 中读取了 (32 + 1) × 4 = 132 字节,写入了 32 × 4 = 128 字节,执行了 64 个 FLOPs,因而计算访存比为 $\frac{64K}{128 + 132K} < \frac{1}{2}$,即平均来看每个 FLOP 至少需要读取 2 个字节。官方给出的 RTX 2080 Ti FP32 计算能力是每秒 14.2 TFLOP/s,因此如果要跑满全部的计算单元则需要 GPU 的内存系统提供至少 14.2 / 0.5 = 28.4 TB/s 的吞吐量,这远大于 RTX 2080 Ti 显存的吞吐量 616 GB/s。因此通过这样的计算我们知道了这种朴素的实现是会被 Global Memory 的带宽所狠狠地限制住的。
实现二:Thread Block-Level Tiling 优化 通过上述分析我们知道要优化矩阵乘法就必须提高内存访问的吞吐量,因而可以考虑使用 Shared Memory 来进行优化。但问题是同时 Shared Memory 也更小,对于评测使用的 RTX 2080 Ti 而言,Global Memory 有 11 GiB,而每个 Streaming Processor (SM) 上的 L1 缓存/Shared Memory 只有 96 KiB,所有 68 个 SM 加起来也只有 6.375 MiB(事实上现代计算机的存储体系都有这样的金字塔结构——越快的存储器空间越小),因此对于稍微大一些的输入规模,就不可能将全部的 $\mathbf{A}$ 和 $\mathbf{B}$ 存入到 Shared Memory 中。
解决这个问题的通常思路是考虑 Tiling,说实话这个词我到现在也不理解它是怎么来的,但是意识流的想法就是——既然快的内存很小,那么就可以将要执行的任务分组,使得每组所需要的数据都能存在这个快而小的内存中。至于分完组之后是每组的执行是串行还是并行,并行的话如何分配给不同的执行单元和如何分组本身是无关的(从这个角度来说应该叫做分治更合理🤔?)。
在矩阵乘法中,我们需要计算矩阵 $\mathbf{C}$ 的 $M \times N$ 个元素的值,如果利用这个「分组」的思想,就可以得到如下图所示的思路:
Thread Block-Level Tiling 优化
我们先考虑在 $M$ 和 $N$ 这两个维度上进行分组 (Tile),将矩阵 $\mathbf{C}$ 划分成 $\lceil \frac{M}{T_M}\rceil \times \lceil \frac{N}{T_N}\rceil$ 组,每组的大小为 $T_M \times T_N$,称之为一个 $\mathbf{C}_\text{tile}$。分组之后,每个 $\mathbf{C}_\text{tile}$ 所需要的 $\mathbf{A}$ 和 $\mathbf{B}$ 中的元素的数目为 $T_M \times K$ 和 $K \times T_N$,因为 $K$ 可能很大,会导致对应的 $\mathbf{A}$ 和 $\mathbf{B}$ 中的元素没法完全放入到 Shared Memory 中。为了解决这个问题,我们进一步考虑在 $K$ 这个维度上进行分组,每组的大小为 $T_K$,这样对应到的矩阵 $\mathbf{A}$ 和 $\mathbf{B}$ 上所需要存储到 Shared Memory 的元素个数就变成了 $T_M \times {\color{red}T_K}$ 和 ${\color{red}T_K} \times T_N$,因此需要通过设置合适的 $T_M$、$T_N$ 和 $T_K$ 就可以将对应的 $\mathbf{A}_\text{tile}$ 和 $\mathbf{B}_\text{tile}$ 放到 Shared Memory 中,省略了很多细节之后的伪代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
__shared__ float sA [ TILE_M ][ TILE_K ];
__shared__ float sB [ TILE_K ][ TILE_N ];
float sum [ TILE_M / C_BLOCK_Y ][ TILE_N / C_BLOCK_X ];
bm = blockIdx . x * TILE_M ;
bn = blockIdx . y * TILE_N ;
for bk in range ( 0 , K , step = TILE_K ) :
__syncthreads ();
sA = LoadGlobalMemory ( A [ bm ... bm + TILE_M ][ bk ... bn + TILE_K ]);
sB = LoadGlobalMemory ( B [ bk ... bn + TILE_K ][ bn ... bn + TILE_N ]);
__syncthreads ();
sum += MatMul ( sA , sB );
StoreGlobalMemory ( C [ bm ... bm + TILE_M ][ bn ... bn + TILE_N ], sum );
稍微解释以下这段代码,处理 $M$ 和 $N$ 维度上的不同分组是可以并行的,因为它们写回到 $\mathbf{C}$ 中不同的区域,因而没有数据依赖,但 $K$ 维度上不同分组之间的计算结果是需要加起来的,因此不太好直接并行。伪代码中高亮行的循环循环就是遍历在 $K$ 这个维度上的所有分组。
$M$ 和 $N$ 维度上的分组的并行要稍微复杂一些,因为分组的大小 $T_M \times T_N$ 可以多于线程块中的线程数目,假设在计算 MatMul(sA, sB) 时线程块的形状为 $C_y \times C_x$,那么每个线程需要负责处理 $\frac{T_M}{C_y} \times \frac{T_N}{C_x}$ 个元素,这也是为什么代码中会出现 C_BLOCK_Y 和 C_BLOCK_X 这两个变量。实际上除了线程块大小外,线程块内线程的排布也是很有讲究的,在 Warp-Level Tiling 优化 中会更加详细地探讨这一点。另外,实际上在读取 $A_\text{tile}$ 和 $B_\text{tile}$ 到 Shared Memory 的时候也存在类似的情况——读取的元素可能大于线程块内线程数目,同时线程块内线程的排布也会影响整体性能。因此在实现中我引入了 A_BLOCK_Y、A_BLOCK_X、B_BLOCK_Y 和 B_BLOCK_X 来表示读取 $A_\text{tile}$ 和 $B_\text{tile}$ 时线程块的形状。
在考虑上述因素之后,通过 Shared Memory 来进行 Thread Block-Level Tiling 优化后的矩阵乘法代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
template < uint32_t TILE_M , uint32_t TILE_N , uint32_t TILE_K , //
uint32_t A_BLOCK_X , uint32_t A_BLOCK_Y , //
uint32_t B_BLOCK_X , uint32_t B_BLOCK_Y , //
uint32_t C_BLOCK_X , uint32_t C_BLOCK_Y >
__global__ __launch_bounds__ ( 256 , 2 ) void gemm_fp32_v2 (
uint32_t M , uint32_t N , uint32_t K , //
const float * __restrict__ A , //
const float * __restrict__ B , //
float * __restrict__ C ) {
static_assert ( A_BLOCK_X * A_BLOCK_Y == C_BLOCK_X * C_BLOCK_Y );
static_assert ( B_BLOCK_X * B_BLOCK_Y == C_BLOCK_X * C_BLOCK_Y );
constexpr const uint32_t C_ITER_Y = TILE_M / C_BLOCK_Y ;
constexpr const uint32_t C_ITER_X = TILE_N / C_BLOCK_X ;
static_assert ( C_ITER_Y * C_BLOCK_Y == TILE_M );
static_assert ( C_ITER_X * C_BLOCK_X == TILE_N );
constexpr const uint32_t A_ITER_Y = TILE_M / A_BLOCK_Y ;
constexpr const uint32_t A_ITER_X = TILE_K / A_BLOCK_X ;
static_assert ( A_ITER_Y * A_BLOCK_Y == TILE_M );
static_assert ( A_ITER_X * A_BLOCK_X == TILE_K );
constexpr const uint32_t B_ITER_Y = TILE_K / B_BLOCK_Y ;
constexpr const uint32_t B_ITER_X = TILE_N / B_BLOCK_X ;
static_assert ( B_ITER_Y * B_BLOCK_Y == TILE_K );
static_assert ( B_ITER_X * B_BLOCK_X == TILE_N );
__shared__ float sA [ TILE_M ][ TILE_K ];
__shared__ float sB [ TILE_K ][ TILE_N ];
float sum [ C_ITER_Y ][ C_ITER_X ] = { 0.0f };
const uint32_t bm = blockIdx . y * TILE_M ;
const uint32_t bn = blockIdx . x * TILE_N ;
for ( uint32_t bk = 0 ; bk < K ; bk += TILE_K ) {
__syncthreads ();
Iterate < A_ITER_Y > ([ & ] < uint32_t iy > {
Iterate < A_ITER_X > ([ & ] < uint32_t ix > {
const uint32_t lm = iy * A_BLOCK_Y + threadIdx . x / A_BLOCK_X ;
const uint32_t lk = ix * A_BLOCK_X + threadIdx . x % A_BLOCK_X ;
const uint32_t gm = bm + lm ;
const uint32_t gk = bk + lk ;
if ( gm < M && gk < K ) {
sA [ lm ][ lk ] = A [ gm * K + gk ];
} else {
sA [ lm ][ lk ] = 0 ;
}
});
});
Iterate < B_ITER_Y > ([ & ] < uint32_t iy > {
Iterate < B_ITER_X > ([ & ] < uint32_t ix > {
const uint32_t lk = iy * B_BLOCK_Y + threadIdx . x / B_BLOCK_X ;
const uint32_t ln = ix * B_BLOCK_X + threadIdx . x % B_BLOCK_X ;
const uint32_t gk = bk + lk ;
const uint32_t gn = bn + ln ;
if ( gk < K && gn < N ) {
sB [ lk ][ ln ] = B [ gk * N + gn ];
} else {
sB [ lk ][ ln ] = 0 ;
}
});
});
__syncthreads ();
Iterate < C_ITER_Y > ([ & ] < uint32_t iy > {
Iterate < C_ITER_X > ([ & ] < uint32_t ix > {
const uint32_t lm = iy * C_BLOCK_Y + threadIdx . x / C_BLOCK_X ;
const uint32_t ln = ix * C_BLOCK_X + threadIdx . x % C_BLOCK_X ;
Iterate < TILE_K > ([ & ] < uint32_t lk > {
sum [ iy ][ ix ] += sA [ lm ][ lk ] * sB [ lk ][ ln ]; //
});
});
});
}
Iterate < C_ITER_Y > ([ & ] < uint32_t iy > {
Iterate < C_ITER_X > ([ & ] < uint32_t ix > {
const uint32_t gm = bm + iy * C_BLOCK_Y + threadIdx . x / C_BLOCK_X ;
const uint32_t gn = bn + ix * C_BLOCK_X + threadIdx . x % C_BLOCK_X ;
if ( gm < M && gn < N ) {
C [ gm * N + gn ] = sum [ iy ][ ix ];
}
});
});
}
代码中定义了一个函数叫做 Iterate,可以看作是长度固定的循环,但是是通过 C++ 自带的语法糖来展开,其实现如下:
namespace detail {
template < typename T , T T_I , T T_N , bool = ( T_I < T_N ) >
struct IterateImpl {
template < typename CT >
__forceinline__ __host__ __device__ //
static std :: enable_if_t < IsCallableWithTemplate < CT , T_I >>
Evaluate ( CT callable ) {
callable . template operator () < T_I > ();
IterateImpl < T , T_I + 1 , T_N >:: Evaluate ( callable );
}
template < typename CT >
__forceinline__ __host__ __device__ //
static std :: enable_if_t < IsCallable < CT , T_I >>
Evaluate ( CT callable ) {
callable ( T_I );
IterateImpl < T , T_I + 1 , T_N >:: Evaluate ( callable );
}
};
template < typename T , T T_I , T T_N >
struct IterateImpl < T , T_I , T_N , false > {
template < typename CT >
__forceinline__ __host__ __device__ static void Evaluate ( CT callable ) {}
};
} // namespace detail
template < typename T , T T_I , T T_N , typename CallableT >
__forceinline__ __host__ __device__ void Iterate ( CallableT callable ) {
detail :: IterateImpl < T , T_I , T_N >:: Evaluate ( callable );
}
template < typename T , T T_N , typename CallableT >
__forceinline__ __host__ __device__ void Iterate ( CallableT callable ) {
detail :: IterateImpl < T , 0 , T_N >:: Evaluate ( callable );
}
template < auto T_I , decltype ( T_I ) T_N , typename CallableT >
__forceinline__ __host__ __device__ void Iterate ( CallableT callable ) {
detail :: IterateImpl < decltype ( T_I ), T_I , T_N >:: Evaluate ( callable );
}
template < auto T_N , typename CallableT >
__forceinline__ __host__ __device__ void Iterate ( CallableT callable ) {
detail :: IterateImpl < decltype ( T_N ), 0 , T_N >:: Evaluate ( callable );
} 这个东西的好处是可以在循环体内随便写各种 constexpr 表达式,但更主要的原因还是我嫌 #pragma unroll 太丑了🙄。
测试结果 中采用的参数为如下表所示:
参数名称 参数值 意义 TILE_M128 $M$ 维度分组大小 $T_M$TILE_N128 $N$ 维度分组大小 $T_N$TILE_K8 $K$ 维度分组大小 $T_K$(A_BLOCK_X, A_BLOCK_Y)(8, 32) 读取 $\mathbf{A}_\text{tile}$ 时线程块形状 (B_BLOCK_X, B_BLOCK_Y)(32, 8) 读取 $\mathbf{B}_\text{tile}$ 时线程块形状 (C_BLOCK_X, C_BLOCK_Y)(16, 16) 计算 $\mathbf{C}_\text{tile}$ 时线程块形状
结果表明通过这种 Shared Memory 进行 Thread Block Tiling 优化可以达到了 cuBLAS 性能的 71.6%,和暴力实现相比有接近一个数量级的加速。
那么通过这种这种 Tiling 的方式为什么能获得这么大的加速呢?我们通过 Tiling 将矩阵 $\mathbf{C}$ 划分成了 $\frac{M}{T_M} \times \frac{N}{T_N}$ 个分组,每组由一个线程块负责进行 $\frac{K}{T_K}$ 次循环,对于每次循环而言,每个线程块会:
读取 $T_M T_K$ 个矩阵 $\mathbf{A}$ 中的元素 读取 $T_K T_N$ 个矩阵 $\mathbf{B}$ 中的元素 通过 $T_M T_N T_K$ 次 FFMA 计算 $\mathbf{C}_\text{tile} = \mathbf{A}_\text{tile} \times \mathbf{B}_\text{tile}$,可以看作是 $2T_MT_NT_K$ 个 FLOPs 循环结束时会写回到 $\mathbf{C}$ 中的 $T_MT_N$ 个元素。如果在算计算访存比时只考虑 Global Memory,那么 Thread Block Tiling 优化之后每个线程块的计算访存比为 $\frac{\frac{K}{T_K}\times2T_MT_NT_K}{\frac{K}{T_K}\left(4T_MT_K + 4T_KT_N\right) + 4T_MT_N} = \frac{1}{\frac{2}{T_M} + \frac{2}{T_N} + \frac{2}{K}}$。
从计算访存比的公式中我们可以得到如下结论:
计算访存比与 $T_K$ 无关; $T_M$ 和 $T_N$ 越大,计算访存比越大,对我们就更有利;如果要在每个线程块能取的 Shared Memory 的大小 $4T_K(T_M + T_N)$ 固定的条件下最大化计算访存比 $\frac{1}{\frac{2}{T_M} + \frac{2}{T_N} + \frac{2}{K}}$,通过一些数学变换可以知道 $T_M$ 和 $T_N$ 越接近,计算访存比越大,$T_M = T_N$ 时(如果可行)取到极大值; 看起来我们只需要取 $T_K = 1$,取 $T_M = T_N$ 并开到 Shared Memory 能承受的最大值即可。但事实是,$T_M$ 和 $T_N$ 越大每个线程中需要开的寄存器数量为 $\frac{T_M}{C_y}\times \frac{T_N}{C_x}$ 也就越多,每个线程块需要的 Shared Memory 也就越大,这两者会导致每个 SM 上能同时存在的线程块大小减少,进而可能造成 Warp 数量不够,不能很好地隐藏读取 Global Memory 的延时,从而导致我们前面的以内存带宽为主的分析失效;而如果只取 $T_K = 1$,那么考虑在读取 $\mathbf{A}_\text{tile}$ 时我们读取的是矩阵 $\mathbf{A}$ 的一列,这是一个 Strided Memory Access,既对缓存不友好也无法触发合并访存,因此会增大 Global Memory 访问的延时,导致其不能被隐藏。
实验中,我取了前人 一样的参数,即 $T_M = T_N = 128$,$T_K = 8$,在 $K$ 很大的情况下,算出来的计算访存比为 32,因此只需要显存提供 14.2 / 32 = 0.444 TB/s = 454 GB/s 的吞吐量就好了,这样 Global Memory 就不再是限制性能瓶颈了,因而和暴力实现相比也能获得很大的加速。
如果用 Nsight Compute 跑一下实现二 的代码,会发现当前造成 Warp Stall 的原因是 Stall MIO Throttle,说明此时对 Shared Memory 的指令数目太多了,因此还有进一步加速的空间。
参考文章 里作者使用了每个 SM 每个 cycle 的理论带宽进行了计算访存比的理论分析。
实现三:Thread-Level Tiling 优化 要优化 Shared Memory 的访存,我们就需要考虑到内存系统中比 Shared Memory 更快的硬件——寄存器,原理其实和实现二中减少 Global Memory 的想法一样,在计算 $C_\text{tile} = A_\text{tile} \times B_\text{tile}$ 时,每个线程负责计算 $\frac{T_M}{C_y} \times \frac{T_N}{C_x}$ 个 $C_\text{tile}$ 中元素的计算,我们同样可以进行分组——分成 $\frac{T_M}{R_MC_y} \times \frac{T_N}{R_NC_x}$ 组,每组负责计算 $R_M \times R_N$ 个$C_\text{tile}$ 中的元素,每组由一个线程负责(故而称之为 Thread-Level Tiling),在 $T_K$ 这个维度上也可以分组,每组负责 $R_K$ 个元素,因为只有当前线程负责所有分组,所以每个分组都由每个线程的内部循环负责,如下图所示(其中 $\mathbf{A}_\text{tile per thread}$、$\mathbf{B}_\text{tile per thread}$、$\mathbf{C}_\text{tile per thread}$ 分别表示在实现二中 $\mathbf{A}_\text{tile}$、$\mathbf{B}_\text{tile}$、$\mathbf{C}_\text{tile}$ 分配到当前线程所需要处理的 Tile):
Thread-Level Tiling 优化
和 Thread Block-Level Tiling 不同的是,不同于在 Thread Block-Level Tiling 中需要考虑到合并对 Global Memory 访问的问题,在 Thread-Level Tiling 中我们访问的是 Shared Memory,GPU 上并没有合并访问 Shared Memory 的机制,类似于前面的分析我们知道计算访存比和 $R_K$ 的大小无关,因此为了减少寄存器的使用可以大胆地取 $R_K = 1$,这样看起来 $\mathbf{C}_\text{frag} = \mathbf{A}_\text{frag} \times \mathbf{B}_\text{frag}$ 就像是两个向量做外积,这也是为什么很多前人的文章都提到向量外积 这一点,但我觉得当作 Thread-Level Tiling 取 $R_K = 1$ 是一个更加合理的理解。另外,和每个线程中存储 $\mathbf{C}$ 结果的 64 个寄存器比起来,如果使用实现二的设定,$\frac{T_M}{C_y} = \frac{T_N}{C_x} = 8$ 并不是什么很大的数字,因此直接取 $R_M = \frac{T_M}{C_y}$ 和 $R_N = \frac{T_N}{C_x}$ 即可(只多了额外 16 个寄存器来存 $\mathbf{A}_\text{frag}$ 和 $\mathbf{B}_\text{frag}$)。
这个方案所得到的代码如下(注意高亮行,它是和实现二唯一的不同之处):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
template < uint32_t TILE_M , uint32_t TILE_N , uint32_t TILE_K , //
uint32_t A_BLOCK_X , uint32_t A_BLOCK_Y , //
uint32_t B_BLOCK_X , uint32_t B_BLOCK_Y , //
uint32_t C_BLOCK_X , uint32_t C_BLOCK_Y >
__global__ __launch_bounds__ ( 256 , 2 ) void gemm_fp32_v3 (
uint32_t M , uint32_t N , uint32_t K , //
const float * __restrict__ A , //
const float * __restrict__ B , //
float * __restrict__ C ) {
static_assert ( A_BLOCK_X * A_BLOCK_Y == C_BLOCK_X * C_BLOCK_Y );
static_assert ( B_BLOCK_X * B_BLOCK_Y == C_BLOCK_X * C_BLOCK_Y );
constexpr const uint32_t C_ITER_Y = TILE_M / C_BLOCK_Y ;
constexpr const uint32_t C_ITER_X = TILE_N / C_BLOCK_X ;
static_assert ( C_ITER_Y * C_BLOCK_Y == TILE_M );
static_assert ( C_ITER_X * C_BLOCK_X == TILE_N );
constexpr const uint32_t A_ITER_Y = TILE_M / A_BLOCK_Y ;
constexpr const uint32_t A_ITER_X = TILE_K / A_BLOCK_X ;
static_assert ( A_ITER_Y * A_BLOCK_Y == TILE_M );
static_assert ( A_ITER_X * A_BLOCK_X == TILE_K );
constexpr const uint32_t B_ITER_Y = TILE_K / B_BLOCK_Y ;
constexpr const uint32_t B_ITER_X = TILE_N / B_BLOCK_X ;
static_assert ( B_ITER_Y * B_BLOCK_Y == TILE_K );
static_assert ( B_ITER_X * B_BLOCK_X == TILE_N );
__shared__ float sA [ TILE_M ][ TILE_K ];
__shared__ float sB [ TILE_K ][ TILE_N ];
float sum [ C_ITER_Y ][ C_ITER_X ] = { 0.0f };
float fA [ C_ITER_Y ];
float fB [ C_ITER_X ];
const uint32_t bm = blockIdx . y * TILE_M ;
const uint32_t bn = blockIdx . x * TILE_N ;
for ( uint32_t bk = 0 ; bk < K ; bk += TILE_K ) {
__syncthreads ();
Iterate < A_ITER_Y > ([ & ] < uint32_t iy > {
Iterate < A_ITER_X > ([ & ] < uint32_t ix > {
const uint32_t lm = iy * A_BLOCK_Y + threadIdx . x / A_BLOCK_X ;
const uint32_t lk = ix * A_BLOCK_X + threadIdx . x % A_BLOCK_X ;
const uint32_t gm = bm + lm ;
const uint32_t gk = bk + lk ;
if ( gm < M && gk < K ) {
sA [ lm ][ lk ] = A [ gm * K + gk ];
} else {
sA [ lm ][ lk ] = 0 ;
}
});
});
Iterate < B_ITER_Y > ([ & ] < uint32_t iy > {
Iterate < B_ITER_X > ([ & ] < uint32_t ix > {
const uint32_t lk = iy * B_BLOCK_Y + threadIdx . x / B_BLOCK_X ;
const uint32_t ln = ix * B_BLOCK_X + threadIdx . x % B_BLOCK_X ;
const uint32_t gk = bk + lk ;
const uint32_t gn = bn + ln ;
if ( gk < K && gn < N ) {
sB [ lk ][ ln ] = B [ gk * N + gn ];
} else {
sB [ lk ][ ln ] = 0 ;
}
});
});
__syncthreads ();
Iterate < TILE_K > ([ & ] < uint32_t lk > {
Iterate < C_ITER_Y > ([ & ] < uint32_t iy > {
const uint32_t lm = iy * C_BLOCK_Y + threadIdx . x / C_BLOCK_X ;
fA [ iy ] = sA [ lm ][ lk ];
});
Iterate < C_ITER_X > ([ & ] < uint32_t ix > {
const uint32_t ln = ix * C_BLOCK_X + threadIdx . x % C_BLOCK_X ;
fB [ ix ] = sB [ lk ][ ln ];
});
Iterate < C_ITER_Y > ([ & ] < uint32_t iy > {
Iterate < C_ITER_X > ([ & ] < uint32_t ix > {
sum [ iy ][ ix ] += fA [ iy ] * fB [ ix ]; //
});
});
});
}
Iterate < C_ITER_Y > ([ & ] < uint32_t iy > {
Iterate < C_ITER_X > ([ & ] < uint32_t ix > {
const uint32_t gm = bm + iy * C_BLOCK_Y + threadIdx . x / C_BLOCK_X ;
const uint32_t gn = bn + ix * C_BLOCK_X + threadIdx . x % C_BLOCK_X ;
if ( gm < M && gn < N ) {
C [ gm * N + gn ] = sum [ iy ][ ix ];
}
});
});
}
可惜的是测试结果 表明,通过这种方式实现并没有带来任何可观测的性能提升(甚至变慢了),猜测可能是在实现二中编译器进行了优化,结果和手动做 Thread-Level Tiling 的实现三是一样的。通过观察 SASS 汇编代码发现的确如此,这两种实现方式都只包含了 128 条 LDS.U 指令,而如果不做任何优化的话前者应该是 2 × 8 × 8 × 8 = 1024 条 LDS.U 指令(参考文章 中也提到了编译器优化自动通过 Thread-Tiling 优化这一点)。
实现四:向量化读写 Shared Memory 官方给出的 Stall MIO Throttle 的原因有三种:
特殊数学指令; Dynamic Branching; Shared Memory 内存访问; 第一条指的是我们是否使用了类似于 sinfLDS.128 和 STS.128 指令。换句话说,原来每个线程只从 Shared Memory 中读/写 1 个数,现在要让它读/写连续的 4 个数。
但是这样做会碰到一个问题,就是 LDS.128 或 STS.128 只能让每个线程读/写 Shared Memory 中同一行 中连续的 4 列。但在 Thread-Level Tiling 中,我们取了 $R_K = 1$,因此每个线程要读取的 $\mathbf{A}_\text{frag}$ 是矩阵 $\mathbf{A}$ 中同一列 中的元素,为了达到这一点,在 Shared Memory 中只能存储 $\mathbf{A}_\text{tile}$ 的转置。如下图所示,如果在 Shared Memory 中存储 $\mathbf{A}_\text{tile}$ 的转置,那么在写入 Shared Memory 时,一个 1/4 Warp 中线程存储的元素实际上是 Shared Memory 中的同一列(图中只画了 1/8 个 Warp),这些列都在一个 Bank 上,因此会造成 Bank Conflict。
每个线程在 Global Memory 和 Shared Memory 的访存
为了解决这一点,我们可以采用一种特殊的排列来使写访存所需要的 Bank 错开,和矩阵转置一样,最简单的想法是直接 Pad 最后一列,这样每一行中同样的列对应到的 Bank 就错开了。但不用 Pad 也可以手动做到这一点,大致的想法是,如果说原来每个线程要读取或写入 Shared Memory 中 $k$ 行中第 $4m, 4m + 1, 4m + 2, 4m + 3$ 列,那么就改成读取或写入第 $4t, 4t + 1, 4t + 2, 4t + 3$ 列,其中 $t = (k + m) \bmod 32$,这种方式看起来好像就是列在不同行间循环一样(如下图):
一种避免 Bank Conflict 的方法
这样我们就可以在享受使用向量化访存指令的同时完美地避免 Bank Conflict 了。但正如前面提到的可以用 Pad 来避免 Bank Conflict 一样,当然实际实现中可采取的方法不止一种,每种方法在寄存器资源紧张的情况下会有微妙的差异(见实现六 )。
实现的代码如下(其中高亮行表示避免 Bank Conflict 的部分):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
__global__ __launch_bounds__ ( 256 , 2 ) void gemm_fp32_v4_128x128x8 (
uint32_t M , uint32_t N , uint32_t K , //
const float * __restrict__ A , //
const float * __restrict__ B , //
float * __restrict__ C ) {
constexpr const uint32_t TILE_M = 128 ;
constexpr const uint32_t TILE_N = 128 ;
constexpr const uint32_t TILE_K = 8 ;
constexpr const uint32_t A_BLOCK_Y = 32 ;
constexpr const uint32_t A_BLOCK_X = 8 ;
constexpr const uint32_t B_BLOCK_Y = 8 ;
constexpr const uint32_t B_BLOCK_X = 32 ;
constexpr const uint32_t C_BLOCK_Y = 16 ;
constexpr const uint32_t C_BLOCK_X = 16 ;
static_assert ( A_BLOCK_X * A_BLOCK_Y == C_BLOCK_X * C_BLOCK_Y );
static_assert ( B_BLOCK_X * B_BLOCK_Y == C_BLOCK_X * C_BLOCK_Y );
constexpr const uint32_t C_ITER_Y = TILE_M / C_BLOCK_Y ;
constexpr const uint32_t C_ITER_X = TILE_N / C_BLOCK_X ;
static_assert ( C_ITER_Y * C_BLOCK_Y == TILE_M );
static_assert ( C_ITER_X * C_BLOCK_X == TILE_N );
static_assert ( C_ITER_Y % 4 == 0 );
static_assert ( C_ITER_X % 4 == 0 );
constexpr const uint32_t A_ITER_Y = TILE_M / A_BLOCK_Y ;
constexpr const uint32_t A_ITER_X = TILE_K / A_BLOCK_X ;
static_assert ( A_ITER_Y * A_BLOCK_Y == TILE_M );
static_assert ( A_ITER_X * A_BLOCK_X == TILE_K );
static_assert ( A_ITER_Y % 4 == 0 );
constexpr const uint32_t B_ITER_Y = TILE_K / B_BLOCK_Y ;
constexpr const uint32_t B_ITER_X = TILE_N / B_BLOCK_X ;
static_assert ( B_ITER_Y * B_BLOCK_Y == TILE_K );
static_assert ( B_ITER_X * B_BLOCK_X == TILE_N );
static_assert ( B_ITER_X % 4 == 0 );
__shared__ float sA [ TILE_K ][ TILE_M ];
__shared__ float sB [ TILE_K ][ TILE_N ];
float sum [ C_ITER_Y ][ C_ITER_X ] = { 0.0f };
float rA [ A_ITER_Y ][ A_ITER_X ];
float rB [ B_ITER_Y ][ B_ITER_X ];
float fA [ C_ITER_Y ];
float fB [ C_ITER_X ];
const uint32_t bm = blockIdx . y * TILE_M ;
const uint32_t bn = blockIdx . x * TILE_N ;
for ( uint32_t bk = 0 ; bk < K ; bk += TILE_K ) {
__syncthreads ();
Iterate < A_ITER_Y > ([ & ] < uint32_t iy > {
Iterate < A_ITER_X > ([ & ] < uint32_t ix > {
const uint32_t lm = iy * A_BLOCK_Y + threadIdx . x / A_BLOCK_X ;
const uint32_t lk = ix * A_BLOCK_X + threadIdx . x % A_BLOCK_X ;
const uint32_t gm = bm + lm ;
const uint32_t gk = bk + lk ;
if ( gm < M && gk < K ) {
rA [ iy ][ ix ] = A [ gm * K + gk ];
} else {
rA [ iy ][ ix ] = 0 ;
}
});
});
Iterate < B_ITER_Y > ([ & ] < uint32_t iy > {
Iterate < B_ITER_X > ([ & ] < uint32_t ix > {
const uint32_t lk = iy * B_BLOCK_Y + threadIdx . x / B_BLOCK_X ;
const uint32_t ln = ix * B_BLOCK_X + threadIdx . x % B_BLOCK_X ;
const uint32_t gk = bk + lk ;
const uint32_t gn = bn + ln ;
if ( gk < K && gn < N ) {
rB [ iy ][ ix ] = B [ gk * N + gn ];
} else {
rB [ iy ][ ix ] = 0 ;
}
});
});
Iterate < A_ITER_Y / 4 > ([ & ] < uint32_t iy > {
Iterate < A_ITER_X > ([ & ] < uint32_t ix > {
const uint32_t lk = ix * A_BLOCK_X + threadIdx . x % A_BLOCK_X ;
const uint32_t lm = iy * A_BLOCK_Y + threadIdx . x / A_BLOCK_X ;
reinterpret_cast < float4 *> ( sA [ lk ])[( lm + lk ) % 32 ] = float4 {
rA [ iy * 4 + 0 ][ ix ],
rA [ iy * 4 + 1 ][ ix ],
rA [ iy * 4 + 2 ][ ix ],
rA [ iy * 4 + 3 ][ ix ],
};
});
});
Iterate < B_ITER_Y > ([ & ] < uint32_t iy > {
Iterate < B_ITER_X / 4 > ([ & ] < uint32_t ix > {
const uint32_t lk = iy * B_BLOCK_Y + threadIdx . x / B_BLOCK_X ;
const uint32_t ln = ix * B_BLOCK_X + threadIdx . x % B_BLOCK_X ;
reinterpret_cast < float4 *> ( sB [ lk ])[ ln ] = float4 {
rB [ iy ][ ix * 4 + 0 ],
rB [ iy ][ ix * 4 + 1 ],
rB [ iy ][ ix * 4 + 2 ],
rB [ iy ][ ix * 4 + 3 ],
};
});
});
__syncthreads ();
Iterate < TILE_K > ([ & ] < uint32_t lk > {
Iterate < C_ITER_Y / 4 > ([ & ] < uint32_t iy > {
const uint32_t lm = iy * C_BLOCK_Y + threadIdx . x / C_BLOCK_X ;
reinterpret_cast < float4 *> ( fA )[ iy ] =
reinterpret_cast < float4 *> ( sA [ lk ])[( lm + lk ) % 32 ];
});
Iterate < C_ITER_X / 4 > ([ & ] < uint32_t ix > {
const uint32_t ln = ix * C_BLOCK_X + threadIdx . x % C_BLOCK_X ;
reinterpret_cast < float4 *> ( fB )[ ix ] =
reinterpret_cast < const float4 *> ( sB [ lk ])[ ln ];
});
Iterate < C_ITER_Y > ([ & ] < uint32_t iy > {
Iterate < C_ITER_X > ([ & ] < uint32_t ix > {
sum [ iy ][ ix ] += fA [ iy ] * fB [ ix ]; //
});
});
});
}
Iterate < C_ITER_Y > ([ & ] < uint32_t iy > {
const uint32_t gm = bm + (( iy / 4 ) * C_BLOCK_Y + threadIdx . x / C_BLOCK_X ) +
( iy % 4 ) * A_BLOCK_Y ;
if ( gm < M ) {
Iterate < C_ITER_X > ([ & ] < uint32_t ix > {
const uint32_t gn = bn +
(( ix / 4 ) * C_BLOCK_X + threadIdx . x % C_BLOCK_X ) +
( ix % 4 ) * B_BLOCK_X ;
if ( gn < N ) {
C [ gm * N + gn ] = sum [ iy ][ ix ];
}
});
}
});
}
测试结果 表明这样可以达到 cuBLAS 的 85.4% 性能还算不错了,但是和 cuBLAS 仍然有一定差距。如果用 Profiler 跑一下发现目前 Warp Stall 的原因有四条比较瞩目,即 Stall Long Scoreboard、Stall Barrier、Stall MIO Throttle 和 Stall Short Scoreboard,接下来的实现五和实现六正是要来解决这几点。
实现五:Warp-Level Tiling 优化 Warp MIO Throttle 之前在实现四 中分析过是 Shared Memory 访存造成的,而 Stall Short Scoreboard 也是这样,因此为了解决这两点,我们必须要减少 Shared Memory 访存的 Memory Transaction 数目和延时。减少 Memory Transaction 的数目的办法只有一种,就是利用在读取 Shared Memory 时的广播机制。下图展示了在实现四中的一个 Warp 在 $\mathbf{A}_\text{tile}$ 和 $\mathbf{B}_\text{tile}$ 中的访存(为了直观,实现四 中避免 Bank Conflict 的手法并没有在图中展示,图中灰色的方块表示这个 Warp 在 $k$ 维上第一个循环会读取的元素):
当 $\mathbf{C}_\text{tile}$ 为 16 × 16 时 Warp 中的访存
每次在读取 $\mathbf{A}_\text{tile}$ 中的元素时,由于广播机制这个 Warp 只会发射 2 个 Memory Transcation,而每次在读取 $\mathbf{B}_\text{tile}$ 中的元素时会发射 4 个 Memory Transaction。
关于 Shared Memory 在向量化指令下的访存机制的讨论,可以参考
这一篇文章 。
而如果我们可以把一个 Warp 中的 32 个线程组织成 4 × 8 这种形式,并同时采用 4 × 2 作为一个 Quarter-Tile 的形状(如下图):
当 $\mathbf{C}_\text{tile}$ 为 16 × 16 时,采用 4 × 8 作为 Warp 形状,并把 4 × 2 作为 Quarter-Tile 的形状(蓝色框)时的访存
这样在读取 $\mathbf{A}_\text{tile}$ 中的元素时,由于广播机制这个 Warp 只会发射 2 个 Memory Transcation,在读取 $\mathbf{B}_\text{tile}$ 中的元素时,这个 Warp 同样可以触发广播机制,只发射 2 个 Memory Transaction。
在这篇文章 中作者在代码 中采用了 4 × 8 作为 Warp 形状,并用类似与一种 Z-Order 的方式达到了同样只需要 4 个 Memory Transaction 的效果,事实上,采用如下 2 × 16 的 Warp-Tile 也可以达到同样的效果(只要能触发广播机制怎么都可以)。
当 $\mathbf{C}_\text{tile}$ 为 16 × 16 时,采用 2 × 16 作为 Warp 形状,并按照 Z 型排列线程时的访存
实现了 Warp-Level Tiling 的代码如下(高亮行为相对于实现四的改动):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
__global__ __launch_bounds__ ( 256 , 2 ) void gemm_fp32_v5_128x128x8 (
uint32_t M , uint32_t N , uint32_t K , //
const float * __restrict__ A , //
const float * __restrict__ B , //
float * __restrict__ C ) {
constexpr const uint32_t TILE_M = 128 ;
constexpr const uint32_t TILE_N = 128 ;
constexpr const uint32_t TILE_K = 8 ;
constexpr const uint32_t A_BLOCK_Y = 32 ;
constexpr const uint32_t A_BLOCK_X = 8 ;
constexpr const uint32_t B_BLOCK_Y = 8 ;
constexpr const uint32_t B_BLOCK_X = 32 ;
constexpr const uint32_t C_BLOCK_Y = 16 ;
constexpr const uint32_t C_BLOCK_X = 16 ;
static_assert ( A_BLOCK_X * A_BLOCK_Y == C_BLOCK_X * C_BLOCK_Y );
static_assert ( B_BLOCK_X * B_BLOCK_Y == C_BLOCK_X * C_BLOCK_Y );
constexpr const uint32_t C_ITER_Y = TILE_M / C_BLOCK_Y ;
constexpr const uint32_t C_ITER_X = TILE_N / C_BLOCK_X ;
static_assert ( C_ITER_Y * C_BLOCK_Y == TILE_M );
static_assert ( C_ITER_X * C_BLOCK_X == TILE_N );
static_assert ( C_ITER_Y % 4 == 0 );
static_assert ( C_ITER_X % 4 == 0 );
constexpr const uint32_t A_ITER_Y = TILE_M / A_BLOCK_Y ;
constexpr const uint32_t A_ITER_X = TILE_K / A_BLOCK_X ;
static_assert ( A_ITER_Y * A_BLOCK_Y == TILE_M );
static_assert ( A_ITER_X * A_BLOCK_X == TILE_K );
static_assert ( A_ITER_Y % 4 == 0 );
constexpr const uint32_t B_ITER_Y = TILE_K / B_BLOCK_Y ;
constexpr const uint32_t B_ITER_X = TILE_N / B_BLOCK_X ;
static_assert ( B_ITER_Y * B_BLOCK_Y == TILE_K );
static_assert ( B_ITER_X * B_BLOCK_X == TILE_N );
static_assert ( B_ITER_X % 4 == 0 );
__shared__ float sA [ TILE_K ][ TILE_M ];
__shared__ float sB [ TILE_K ][ TILE_N ];
float sum [ C_ITER_Y ][ C_ITER_X ] = { 0.0f };
float rA [ A_ITER_Y ][ A_ITER_X ];
float rB [ B_ITER_Y ][ B_ITER_X ];
float fA [ C_ITER_Y ];
float fB [ C_ITER_X ];
constexpr const uint32_t C_WARP_Y = 4 ;
constexpr const uint32_t C_WARP_X = 8 ;
static_assert ( C_WARP_Y * C_WARP_X == WARP_SIZE );
constexpr const uint32_t C_NUM_Y_WARPS = C_BLOCK_Y / C_WARP_Y ;
constexpr const uint32_t C_NUM_X_WARPS = C_BLOCK_X / C_WARP_X ;
constexpr const uint32_t C_WARP_LANE_GROUP_Y = 4 ;
constexpr const uint32_t C_WARP_LANE_GROUP_X = 2 ;
constexpr const uint32_t C_WARP_LANE_GROUP_SIZE =
C_WARP_LANE_GROUP_Y * C_WARP_LANE_GROUP_X ;
constexpr const uint32_t C_NUM_WARP_Y_LANE_GROUPS =
C_WARP_Y / C_WARP_LANE_GROUP_Y ;
constexpr const uint32_t C_NUM_WARP_X_LANE_GROUPS =
C_WARP_X / C_WARP_LANE_GROUP_X ;
const uint32_t warp = threadIdx . x / WARP_SIZE ;
const uint32_t lane = threadIdx . x % WARP_SIZE ;
const uint32_t lane_group_gid = lane / C_WARP_LANE_GROUP_SIZE ;
const uint32_t lane_group_lid = lane % C_WARP_LANE_GROUP_SIZE ;
const uint32_t ty =
( warp / C_NUM_X_WARPS ) * C_WARP_Y +
( lane_group_gid / C_NUM_WARP_X_LANE_GROUPS ) * C_WARP_LANE_GROUP_Y +
( lane_group_lid / C_WARP_LANE_GROUP_X );
const uint32_t tx =
( warp % C_NUM_X_WARPS ) * C_WARP_X +
( lane_group_gid % C_NUM_WARP_X_LANE_GROUPS ) * C_WARP_LANE_GROUP_X +
( lane_group_lid % C_WARP_LANE_GROUP_X );
const uint32_t bm = blockIdx . y * TILE_M ;
const uint32_t bn = blockIdx . x * TILE_N ;
for ( uint32_t bk = 0 ; bk < K ; bk += TILE_K ) {
__syncthreads ();
Iterate < A_ITER_Y > ([ & ] < uint32_t iy > {
Iterate < A_ITER_X > ([ & ] < uint32_t ix > {
const uint32_t lm = iy * A_BLOCK_Y + threadIdx . x / A_BLOCK_X ;
const uint32_t lk = ix * A_BLOCK_X + threadIdx . x % A_BLOCK_X ;
const uint32_t gm = bm + lm ;
const uint32_t gk = bk + lk ;
if ( gm < M && gk < K ) {
rA [ iy ][ ix ] = A [ gm * K + gk ];
} else {
rA [ iy ][ ix ] = 0 ;
}
});
});
Iterate < B_ITER_Y > ([ & ] < uint32_t iy > {
Iterate < B_ITER_X > ([ & ] < uint32_t ix > {
const uint32_t lk = iy * B_BLOCK_Y + threadIdx . x / B_BLOCK_X ;
const uint32_t ln = ix * B_BLOCK_X + threadIdx . x % B_BLOCK_X ;
const uint32_t gk = bk + lk ;
const uint32_t gn = bn + ln ;
if ( gk < K && gn < N ) {
rB [ iy ][ ix ] = B [ gk * N + gn ];
} else {
rB [ iy ][ ix ] = 0 ;
}
});
});
Iterate < A_ITER_Y / 4 > ([ & ] < uint32_t iy > {
Iterate < A_ITER_X > ([ & ] < uint32_t ix > {
const uint32_t lk = ix * A_BLOCK_X + threadIdx . x % A_BLOCK_X ;
const uint32_t lm = iy * A_BLOCK_Y + threadIdx . x / A_BLOCK_X ;
reinterpret_cast < float4 *> ( sA [ lk ])[( lm + lk ) % 32 ] = float4 {
rA [ iy * 4 + 0 ][ ix ],
rA [ iy * 4 + 1 ][ ix ],
rA [ iy * 4 + 2 ][ ix ],
rA [ iy * 4 + 3 ][ ix ],
};
});
});
Iterate < B_ITER_Y > ([ & ] < uint32_t iy > {
Iterate < B_ITER_X / 4 > ([ & ] < uint32_t ix > {
const uint32_t lk = iy * B_BLOCK_Y + threadIdx . x / B_BLOCK_X ;
const uint32_t ln = ix * B_BLOCK_X + threadIdx . x % B_BLOCK_X ;
reinterpret_cast < float4 *> ( sB [ lk ])[ ln ] = float4 {
rB [ iy ][ ix * 4 + 0 ],
rB [ iy ][ ix * 4 + 1 ],
rB [ iy ][ ix * 4 + 2 ],
rB [ iy ][ ix * 4 + 3 ],
};
});
});
__syncthreads ();
Iterate < TILE_K > ([ & ] < uint32_t lk > {
Iterate < C_ITER_Y / 4 > ([ & ] < uint32_t iy > {
const uint32_t lm = iy * C_BLOCK_Y + ty ;
reinterpret_cast < float4 *> ( fA )[ iy ] =
reinterpret_cast < float4 *> ( sA [ lk ])[( lm + lk ) % 32 ];
});
Iterate < C_ITER_X / 4 > ([ & ] < uint32_t ix > {
const uint32_t ln = ix * C_BLOCK_X + tx ; // threadIdx.x % C_BLOCK_X;
reinterpret_cast < float4 *> ( fB )[ ix ] =
reinterpret_cast < const float4 *> ( sB [ lk ])[ ln ];
});
Iterate < C_ITER_Y > ([ & ] < uint32_t iy > {
Iterate < C_ITER_X > ([ & ] < uint32_t ix > {
sum [ iy ][ ix ] += fA [ iy ] * fB [ ix ]; //
});
});
});
}
Iterate < C_ITER_Y > ([ & ] < uint32_t iy > {
const uint32_t gm = bm + (( iy / 4 ) * C_BLOCK_Y + ty ) + ( iy % 4 ) * A_BLOCK_Y ;
if ( gm < M ) {
Iterate < C_ITER_X > ([ & ] < uint32_t ix > {
const uint32_t gn =
bn + (( ix / 4 ) * C_BLOCK_X + tx ) + ( ix % 4 ) * B_BLOCK_X ;
if ( gn < N ) {
C [ gm * N + gn ] = sum [ iy ][ ix ];
}
});
}
});
}
测试结果 表明加了 Warp-Level Tiling 之后大概快得不多,提升到了 cuBLAS 的 86.5%,虽然这么说但在这个技巧上的实现是最花时间的,因为需要弄清楚每个线程的编号对应。另外参考文章 虽然写的很好,但是并没有提及为什么 Z 形排列的线程能更好地利用广播机制,于是我单独开了一篇文章 来自己探索这个问题。
通过 Profiler 看到此时 Stall MIO Throttle 和 Stall Short Scoreboard 已经不是主要原因了,但 Stall Long Scoreboard 仍然占比很大(也就是读取 Global Memory 延时没被隐藏住),在下面的优化中我们来解决这个问题。
实现六:Double-Buffering 优化 解决访问 Global Memory 延时太长的主要想法是我们可以开设两份 Shared Memory,一份和前面的实现一样用来做计算,另一份进行 Prefetch。同样的想法也可以在 Shared Memory 到寄存器上实现——开两份 $A_\text{frag}$ 和 $B_\text{frag}$,一份用来做计算,一份用来从 Shared Memory 中读数据,这样计算和访存就可以组成流水线从而进一步隐藏访存延时。除此之外,这样的方法还能减少一次线程块内的同步操作。
一开始我以为这两部分流水线和 Tiling 一样是嵌套的,即 Thread-Block 层面的 Global Memory 到 Shared Memory 的流水线的计算部分中包含了 Thread 层面的 Shared Memory 到寄存器的流水线,后面发现直接按照这个思路实现并不能达到想要的加速效果,因此这部分参考了参考文章 的伪代码实现。因为 Double-Buffer 需要将线程内的寄存器翻倍,为了保证一个 SM 上的 Occupancy,我将实现四 中避免 Bank Conflict 的方式改成的位运算 XOR 来处理(但想法大同小异,注意代码中的高亮行),其实现代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
__global__ void gemm_fp32_v6_128x128x8 ( uint32_t M , uint32_t N , uint32_t K , //
const float * __restrict__ A , //
const float * __restrict__ B , //
float * __restrict__ C ) {
constexpr const uint32_t TILE_M = 128 ;
constexpr const uint32_t TILE_N = 128 ;
constexpr const uint32_t TILE_K = 8 ;
constexpr const uint32_t A_BLOCK_Y = 32 ;
constexpr const uint32_t A_BLOCK_X = 8 ;
constexpr const uint32_t B_BLOCK_Y = 8 ;
constexpr const uint32_t B_BLOCK_X = 32 ;
constexpr const uint32_t C_BLOCK_Y = 16 ;
constexpr const uint32_t C_BLOCK_X = 16 ;
static_assert ( A_BLOCK_X * A_BLOCK_Y == C_BLOCK_X * C_BLOCK_Y );
static_assert ( B_BLOCK_X * B_BLOCK_Y == C_BLOCK_X * C_BLOCK_Y );
constexpr const uint32_t C_ITER_Y = TILE_M / C_BLOCK_Y ;
constexpr const uint32_t C_ITER_X = TILE_N / C_BLOCK_X ;
static_assert ( C_ITER_Y * C_BLOCK_Y == TILE_M );
static_assert ( C_ITER_X * C_BLOCK_X == TILE_N );
static_assert ( C_ITER_Y % 4 == 0 );
static_assert ( C_ITER_X % 4 == 0 );
constexpr const uint32_t A_ITER_Y = TILE_M / A_BLOCK_Y ;
constexpr const uint32_t A_ITER_X = TILE_K / A_BLOCK_X ;
static_assert ( A_ITER_Y * A_BLOCK_Y == TILE_M );
static_assert ( A_ITER_X * A_BLOCK_X == TILE_K );
static_assert ( A_ITER_Y % 4 == 0 );
constexpr const uint32_t B_ITER_Y = TILE_K / B_BLOCK_Y ;
constexpr const uint32_t B_ITER_X = TILE_N / B_BLOCK_X ;
static_assert ( B_ITER_Y * B_BLOCK_Y == TILE_K );
static_assert ( B_ITER_X * B_BLOCK_X == TILE_N );
static_assert ( B_ITER_X % 4 == 0 );
__shared__ float sA [ 2 ][ TILE_K ][ TILE_M ];
__shared__ float sB [ 2 ][ TILE_K ][ TILE_N ];
float sum [ C_ITER_Y ][ C_ITER_X ] = { 0.0f };
float rA [ A_ITER_Y ][ A_ITER_X ];
float rB [ B_ITER_Y ][ B_ITER_X ];
float fA [ 2 ][ C_ITER_Y ];
float fB [ 2 ][ C_ITER_X ];
constexpr const uint32_t C_WARP_Y = 4 ;
constexpr const uint32_t C_WARP_X = 8 ;
static_assert ( C_WARP_Y * C_WARP_X == WARP_SIZE );
constexpr const uint32_t C_NUM_Y_WARPS = C_BLOCK_Y / C_WARP_Y ;
constexpr const uint32_t C_NUM_X_WARPS = C_BLOCK_X / C_WARP_X ;
constexpr const uint32_t C_WARP_LANE_GROUP_Y = 4 ;
constexpr const uint32_t C_WARP_LANE_GROUP_X = 2 ;
constexpr const uint32_t C_WARP_LANE_GROUP_SIZE =
C_WARP_LANE_GROUP_Y * C_WARP_LANE_GROUP_X ;
constexpr const uint32_t C_NUM_WARP_Y_LANE_GROUPS =
C_WARP_Y / C_WARP_LANE_GROUP_Y ;
constexpr const uint32_t C_NUM_WARP_X_LANE_GROUPS =
C_WARP_X / C_WARP_LANE_GROUP_X ;
static_assert ( C_WARP_LANE_GROUP_SIZE == 128 / sizeof ( float4 ));
const uint32_t warp = threadIdx . x / WARP_SIZE ;
const uint32_t lane = threadIdx . x % WARP_SIZE ;
const uint32_t lane_group_gid = lane / C_WARP_LANE_GROUP_SIZE ;
const uint32_t lane_group_lid = lane % C_WARP_LANE_GROUP_SIZE ;
const uint32_t ty =
( warp / C_NUM_X_WARPS ) * C_WARP_Y +
( lane_group_gid / C_NUM_WARP_X_LANE_GROUPS ) * C_WARP_LANE_GROUP_Y +
( lane_group_lid / C_WARP_LANE_GROUP_X );
const uint32_t tx =
( warp % C_NUM_X_WARPS ) * C_WARP_X +
( lane_group_gid % C_NUM_WARP_X_LANE_GROUPS ) * C_WARP_LANE_GROUP_X +
( lane_group_lid % C_WARP_LANE_GROUP_X );
const uint32_t bm = blockIdx . y * TILE_M ;
const uint32_t bn = blockIdx . x * TILE_N ;
auto LoadTileA = [ & ]( uint32_t bk ) {
Iterate < A_ITER_Y > ([ & ] < uint32_t iy > {
Iterate < A_ITER_X > ([ & ] < uint32_t ix > {
const uint32_t lm = iy * A_BLOCK_Y + threadIdx . x / A_BLOCK_X ;
const uint32_t lk = ix * A_BLOCK_X + threadIdx . x % A_BLOCK_X ;
const uint32_t gm = bm + lm ;
const uint32_t gk = bk + lk ;
if ( gm < M && gk < K ) {
rA [ iy ][ ix ] = A [ gm * K + gk ];
} else {
rA [ iy ][ ix ] = 0 ;
}
});
});
};
auto LoadTileB = [ & ]( uint32_t bk ) {
Iterate < B_ITER_Y > ([ & ] < uint32_t iy > {
Iterate < B_ITER_X > ([ & ] < uint32_t ix > {
const uint32_t lk = iy * B_BLOCK_Y + threadIdx . x / B_BLOCK_X ;
const uint32_t ln = ix * B_BLOCK_X + threadIdx . x % B_BLOCK_X ;
const uint32_t gk = bk + lk ;
const uint32_t gn = bn + ln ;
if ( gk < K && gn < N ) {
rB [ iy ][ ix ] = B [ gk * N + gn ];
} else {
rB [ iy ][ ix ] = 0 ;
}
});
});
};
auto SaveTileA = [ & ]( uint32_t id ) {
Iterate < A_ITER_Y / 4 > ([ & ] < uint32_t iy > {
Iterate < A_ITER_X > ([ & ] < uint32_t ix > {
const uint32_t lk = ix * A_BLOCK_X + threadIdx . x % A_BLOCK_X ;
const uint32_t lm = iy * A_BLOCK_Y + ( threadIdx . x / A_BLOCK_X ^ lk );
reinterpret_cast < float4 *> ( sA [ id ][ lk ])[ lm ] = float4 {
rA [ iy * 4 + 0 ][ ix ],
rA [ iy * 4 + 1 ][ ix ],
rA [ iy * 4 + 2 ][ ix ],
rA [ iy * 4 + 3 ][ ix ],
};
});
});
};
auto SaveTileB = [ & ]( uint32_t id ) {
Iterate < B_ITER_Y > ([ & ] < uint32_t iy > {
Iterate < B_ITER_X / 4 > ([ & ] < uint32_t ix > {
const uint32_t lk = iy * B_BLOCK_Y + threadIdx . x / B_BLOCK_X ;
const uint32_t ln = ix * B_BLOCK_X + threadIdx . x % B_BLOCK_X ;
reinterpret_cast < float4 *> ( sB [ id ][ lk ])[ ln ] = float4 {
rB [ iy ][ ix * 4 + 0 ],
rB [ iy ][ ix * 4 + 1 ],
rB [ iy ][ ix * 4 + 2 ],
rB [ iy ][ ix * 4 + 3 ],
};
});
});
};
auto LoadFragment = [ & ] < uint32_t lk > ( uint32_t id ) {
Iterate < C_ITER_Y / 4 > ([ & ] < uint32_t iy > {
const uint32_t lm = iy * C_BLOCK_Y + ( ty ^ lk );
reinterpret_cast < float4 *> ( fA [ lk & 1 ])[ iy ] =
reinterpret_cast < float4 *> ( sA [ id ][ lk ])[ lm ];
});
Iterate < C_ITER_X / 4 > ([ & ] < uint32_t ix > {
const uint32_t ln = ix * C_BLOCK_X + tx ;
reinterpret_cast < float4 *> ( fB [ lk & 1 ])[ ix ] =
reinterpret_cast < const float4 *> ( sB [ id ][ lk ])[ ln ];
});
};
LoadTileA ( 0 );
LoadTileB ( 0 );
SaveTileA ( 0 );
SaveTileB ( 0 );
__syncthreads ();
uint32_t id = 1 ;
LoadFragment . template operator () < 0 > ( id ^ 1 );
for ( uint32_t bk = TILE_K ; bk < K ; bk += TILE_K ) {
Iterate < TILE_K > ([ & ] < uint32_t lk > {
if constexpr ( lk + 1 == TILE_K ) {
SaveTileA ( id );
SaveTileB ( id );
__syncthreads ();
id ^= 1 ;
}
LoadFragment . template operator () < ( lk + 1 ) % TILE_K > ( id ^ 1 );
if constexpr ( lk == 0 ) {
LoadTileA ( bk );
LoadTileB ( bk );
}
Iterate < C_ITER_Y > ([ & ] < uint32_t iy > {
Iterate < C_ITER_X > ([ & ] < uint32_t ix > {
sum [ iy ][ ix ] += fA [ lk & 1 ][ iy ] * fB [ lk & 1 ][ ix ]; //
});
});
});
}
Iterate < TILE_K > ([ & ] < uint32_t lk > {
if constexpr ( lk + 1 < TILE_K ) {
LoadFragment . template operator () < lk + 1 > ( id ^ 1 );
}
Iterate < C_ITER_Y > ([ & ] < uint32_t iy > {
Iterate < C_ITER_X > ([ & ] < uint32_t ix > {
sum [ iy ][ ix ] += fA [ lk & 1 ][ iy ] * fB [ lk & 1 ][ ix ]; //
});
});
});
Iterate < C_ITER_Y > ([ & ] < uint32_t iy > {
const uint32_t gm = bm + (( iy / 4 ) * C_BLOCK_Y + ty ) + ( iy % 4 ) * A_BLOCK_Y ;
if ( gm < M ) {
Iterate < C_ITER_X > ([ & ] < uint32_t ix > {
const uint32_t gn =
bn + (( ix / 4 ) * C_BLOCK_X + tx ) + ( ix % 4 ) * B_BLOCK_X ;
if ( gn < N ) {
C [ gm * N + gn ] = sum [ iy ][ ix ];
}
});
}
});
}
通过 Double-Buffering 优化可以达到接近 92.6% 的 cuBLAS 性能,基本已经逼近硬件极限了,通过 Profiler 发现此时 Warp Stall 的原因如下:
但是对于线程内的运算而言,仍然有一些优化空间,例如一些条件判断我们可以进行事先预处理从而减少冗余计算。
实现七:线程内各种优化 观察了参考文章 的代码发现它比实现六中的代码更快,一方面可能是因为它使用了 PTX,另外一方面发现它预处理了很多东西。实际上在实现六中寄存器资源已经非常紧张了,如果要预处理这不是会导致寄存器爆炸吗?通过一些调整——Warp Tiling 的参数、各种位运算减少寄存器使用、调整 If 语句的顺序、去除已知参数的计算,还有参考了一下 SASS 的寄存器冲突的优化(虽然在 CUDA C 上做肯定没啥用,但实测快了一点点),最后得到了如下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
__device__ __forceinline__ void lds_v4_f32 ( float & data0 , float & data1 ,
float & data2 , float & data3 ,
const std :: uint32_t & address ) {
asm volatile ( "ld.shared.v4.f32 {%0, %1, %2, %3}, [%4];"
: "=f" ( data0 ), "=f" ( data1 ), "=f" ( data2 ), "=f" ( data3 )
: "r" ( address ));
}
__device__ __forceinline__ void sts_v4_f32 ( const float & data0 , const float & data1 ,
const float & data2 , const float & data3 ,
const std :: uint32_t & address ) {
asm volatile ( "st.shared.v4.f32 [%0], {%1, %2, %3, %4};"
:
: "r" ( address ), "f" ( data0 ), "f" ( data1 ), "f" ( data2 ), "f" ( data3 ));
}
__device__ __forceinline__ void sts_v4_f32 ( const float4 & data ,
const std :: uint32_t & address ) {
sts_v4_f32 ( data . x , data . y , data . z , data . w , address );
}
__device__ __forceinline__ std :: uint32_t GetSMemU32Address ( const void * pointer ) {
std :: uint32_t address ;
asm ( "{ \n\t "
" .reg .u64 u64addr; \n\t "
" cvta.to.shared.u64 u64addr, %1; \n\t "
" cvt.u32.u64 %0, u64addr; \n\t "
"}"
: "=r" ( address )
: "l" ( pointer ));
return address ;
}
__device__ __forceinline__ void ldg_nc_f32 ( float & reg , const void * ptr ,
bool guard ) {
asm volatile (
"{ \n\t "
" .reg .pred p; \n\t "
" setp.ne.b32 p, %2, 0; \n\t "
#if __CUDACC_VER_MAJOR__ > 11 || \
(__CUDACC_VER_MAJOR__ == 11 && __CUDACC_VER_MINOR__ >= 4) && \
__CUDA_ARCH__ >= 750
" @p ld.global.nc.L2::64B.f32 %0, [%1]; \n\t "
#else
" @p ld.global.nc.f32 %0, [%1]; \n\t "
#endif
"}"
: "=f" ( reg )
: "l" ( ptr ), "r" (( int ) guard ));
}
__global__ void gemm_fp32_v7_128x128x8 ( uint32_t M , uint32_t N , uint32_t K , //
const float * __restrict__ A , //
const float * __restrict__ B , //
float * __restrict__ C ) {
__shared__ __align__ ( 8192 ) char smem [ 16384 ];
float sum [ 8 ][ 8 ] = { 0.0f };
float rA [ 4 ];
float rB [ 4 ] = { 0.0f };
float fA [ 2 ][ 8 ];
float fB [ 2 ][ 8 ];
const uint32_t ty = ( threadIdx . x >> 5 << 1 ) | ( threadIdx . x & 1 );
const uint32_t tx = ( threadIdx . x & 0x1f ) >> 1 ;
const uint32_t bm = blockIdx . y << 7 ;
const uint32_t bn = blockIdx . x << 7 ;
const float * A_ldg = A + ( bm ^ ( threadIdx . x >> 3 )) * K + ( threadIdx . x & 0x7 );
const float * B_ldg = B + ( bn ^ ( threadIdx . x & 0x1f )) + ( threadIdx . x >> 5 ) * N ;
float * const C_stg = C + ( bm ^ ty ) * N + ( bn ^ tx );
uint32_t p_smem = ptx :: GetSMemU32Address ( smem );
uint32_t A_sts = p_smem ^ (( threadIdx . x & 0x7 ) << 9 ) ^
((( threadIdx . x >> 3 ) ^ ( threadIdx . x & 0x7 )) << 4 );
uint32_t A_lds = p_smem ^ ( ty << 4 );
p_smem ^= 0x2000 ;
uint32_t B_sts =
p_smem ^ (( threadIdx . x >> 5 ) << 9 ) ^ (( threadIdx . x & 0x1f ) << 4 );
uint32_t B_lds = p_smem ^ ( tx << 4 );
struct Guard {
bool a [ 4 ] = { false };
bool b [ 4 ] = { false };
bool c_m [ 8 ] = { false };
bool c_n [ 8 ] = { false };
} guard ;
{
const uint32_t m = M - bm ;
guard . a [ 0 ] = ( threadIdx . x >> 3 ) < m ;
guard . a [ 1 ] = ( threadIdx . x >> 3 ^ 0x20 ) < m ;
guard . a [ 2 ] = ( threadIdx . x >> 3 ^ 0x40 ) < m ;
guard . a [ 3 ] = ( threadIdx . x >> 3 ^ 0x60 ) < m ;
guard . c_m [ 0 ] = ty < m ;
guard . c_m [ 4 ] = ( ty ^ 0x10 ) < m ;
guard . c_m [ 1 ] = ( ty ^ 0x20 ) < m ;
guard . c_m [ 5 ] = ( ty ^ 0x30 ) < m ;
guard . c_m [ 2 ] = ( ty ^ 0x40 ) < m ;
guard . c_m [ 6 ] = ( ty ^ 0x50 ) < m ;
guard . c_m [ 3 ] = ( ty ^ 0x60 ) < m ;
guard . c_m [ 7 ] = ( ty ^ 0x70 ) < m ;
const uint32_t n = N - bn ;
guard . b [ 0 ] = ( threadIdx . x & 0x1f ) < n ;
guard . b [ 1 ] = ( threadIdx . x & 0x1f ^ 32 ) < n ;
guard . b [ 2 ] = ( threadIdx . x & 0x1f ^ 64 ) < n ;
guard . b [ 3 ] = ( threadIdx . x & 0x1f ^ 96 ) < n ;
guard . c_n [ 0 ] = tx < n ;
guard . c_n [ 4 ] = ( tx ^ 0x10 ) < n ;
guard . c_n [ 1 ] = ( tx ^ 0x20 ) < n ;
guard . c_n [ 5 ] = ( tx ^ 0x30 ) < n ;
guard . c_n [ 2 ] = ( tx ^ 0x40 ) < n ;
guard . c_n [ 6 ] = ( tx ^ 0x50 ) < n ;
guard . c_n [ 3 ] = ( tx ^ 0x60 ) < n ;
guard . c_n [ 7 ] = ( tx ^ 0x70 ) < n ;
}
auto LoadTileA = [ & ] {
ptx :: ldg_nc_f32 ( rA [ 0 ], A_ldg , guard . a [ 0 ]);
ptx :: ldg_nc_f32 ( rA [ 1 ], A_ldg + 0x20 * K , guard . a [ 1 ]);
ptx :: ldg_nc_f32 ( rA [ 2 ], A_ldg + 0x40 * K , guard . a [ 2 ]);
ptx :: ldg_nc_f32 ( rA [ 3 ], A_ldg + 0x60 * K , guard . a [ 3 ]);
};
auto LoadTileB = [ & ] {
ptx :: ldg_nc_f32 ( rB [ 0 ], B_ldg , guard . b [ 0 ]);
ptx :: ldg_nc_f32 ( rB [ 1 ], B_ldg + 0x20 , guard . b [ 1 ]);
ptx :: ldg_nc_f32 ( rB [ 2 ], B_ldg + 0x40 , guard . b [ 2 ]);
ptx :: ldg_nc_f32 ( rB [ 3 ], B_ldg + 0x60 , guard . b [ 3 ]);
};
uint32_t bk = (( K & 0x7 ) == 0 ) ? 8 : ( K & 0x7 );
if (( threadIdx . x & 0x7 ) < bk ) {
LoadTileA ();
}
A_ldg += bk ;
ptx :: sts_v4_f32 ( * reinterpret_cast < const float4 *> ( rA ), A_sts );
A_sts ^= 0x1000 ;
if (( threadIdx . x >> 5 ) < bk ) {
LoadTileB ();
}
B_ldg += bk * N ;
ptx :: sts_v4_f32 ( * reinterpret_cast < const float4 *> ( rB ), B_sts );
B_sts ^= 0x1000 ;
__syncthreads ();
auto LoadFragment = [ & ] < uint32_t lk > () {
ptx :: lds_v4_f32 ( fA [ lk & 1 ][ 0 ], fA [ lk & 1 ][ 1 ], fA [ lk & 1 ][ 2 ], fA [ lk & 1 ][ 3 ],
A_lds ^ ( lk << 4 ) ^ ( lk << 9 ));
ptx :: lds_v4_f32 ( fA [ lk & 1 ][ 4 ], fA [ lk & 1 ][ 5 ], fA [ lk & 1 ][ 6 ], fA [ lk & 1 ][ 7 ],
A_lds ^ ( lk << 4 ) ^ ( lk << 9 ) ^ 0x100 );
ptx :: lds_v4_f32 ( fB [ lk & 1 ][ 0 ], fB [ lk & 1 ][ 1 ], fB [ lk & 1 ][ 2 ], fB [ lk & 1 ][ 3 ],
B_lds ^ ( lk << 9 ));
ptx :: lds_v4_f32 ( fB [ lk & 1 ][ 4 ], fB [ lk & 1 ][ 5 ], fB [ lk & 1 ][ 6 ], fB [ lk & 1 ][ 7 ],
B_lds ^ ( lk << 9 ) ^ 0x100 );
};
auto ComputeTile = [ & ] < uint32_t lk > {
Iterate < 8 > ([ & ] < uint32_t ix > {
Iterate < 8 > ([ & ] < uint32_t iy > {
sum [ ix ^ 1 ][ iy ] += fA [ lk & 1 ][ iy ] * fB [ lk & 1 ][ ix ]; //
});
});
};
LoadFragment . template operator () < 0 > ();
for ( bk = ( K - bk ) >> 3 ; bk > 0 ; bk -- ) {
LoadTileA ();
A_ldg += 1 << 3 ;
LoadTileB ();
B_ldg += N << 3 ;
Iterate < 8 > ([ & ] < uint32_t lk > {
if constexpr ( lk + 1 == 8 ) {
ptx :: sts_v4_f32 ( * reinterpret_cast < const float4 *> ( rA ), A_sts );
A_sts ^= 0x1000 ;
ptx :: sts_v4_f32 ( * reinterpret_cast < const float4 *> ( rB ), B_sts );
B_sts ^= 0x1000 ;
__syncthreads ();
A_lds ^= 0x1000 ;
B_lds ^= 0x1000 ;
}
LoadFragment . template operator () < ( lk + 1 ) % 8 > ();
ComputeTile . template operator () < lk > ();
});
}
Iterate < 8 > ([ & ] < uint32_t lk > {
if constexpr ( lk + 1 < 8 ) {
LoadFragment . template operator () < lk + 1 > ();
}
ComputeTile . template operator () < lk > ();
});
Iterate < 8 > ([ & ] < uint32_t iy > {
if ( guard . c_m [ iy ]) {
constexpr const uint32_t gm = ( iy >> 2 << 4 ) + (( iy & 3 ) << 5 );
Iterate < 8 > ([ & ] < uint32_t ix > {
if ( guard . c_n [ ix ]) {
constexpr const uint32_t gn = ( ix >> 2 << 4 ) + (( ix & 3 ) << 5 );
C_stg [ gm * N + gn ] = sum [ ix ^ 1 ][ iy ];
}
});
}
});
}
注意这里我没有加上 __launch_bounds__,因为发现很奇怪的是加了这玩意仍然会爆寄存器。测试结果表明这些小优化能提升不少(相比于前面某些优化而言),最后能做到 cuBLAS 的 98.7%,猜想除了能预处理一些结果减少冗余计算之外,另一方面可能改善了流水线的平衡,让访存和计算能更好地重叠起来。不过说是这么说也没法验证这一点了~
总结 这篇文章其实写了挺久的,代码也调了挺久(nvcc 的寄存器总是爆)。通过这篇文章可以看到要写出高性能的代码水还是挺深的。那么是不是矩阵乘法的优化就到此为止了呢?再进一步的优化就需要通过改 SASS 汇编去处理寄存器的 Bank Conflict 这些问题了(有时间的话可能会单独开一篇来探索一下)。另外虽然在很规整的 GPU 上执行形状很规整的矩阵乘法那可能是已经被探索干净了,但是如果考虑到新的硬件(比如下篇要开的坑 FP16 GEMM 和 TensorCore)或者是不规整的形状(比如退化成 GEMV),又或者是考虑矩阵乘法和其他算子的 Fusion 导致 Shared Memory 或者寄存器不够需要重新权衡不同设计的时候,默认矩阵乘法策略可能就没法派上用场了。当然弄这玩意我觉得还有一个理由——就是好玩😝,没别的。
参考 [施工中] CUDA GEMM 理论性能分析与 kernel 优化 深入浅出GPU优化系列:GEMM优化(一) 深入浅出GPU优化系列:GEMM优化(二) 深入浅出GPU优化系列:GEMM优化(三) How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog CUDA矩阵乘法的优化 传统 CUDA GEMM 不完全指北